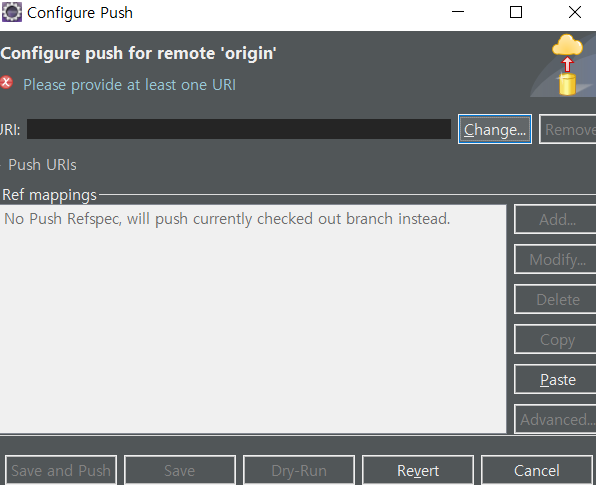
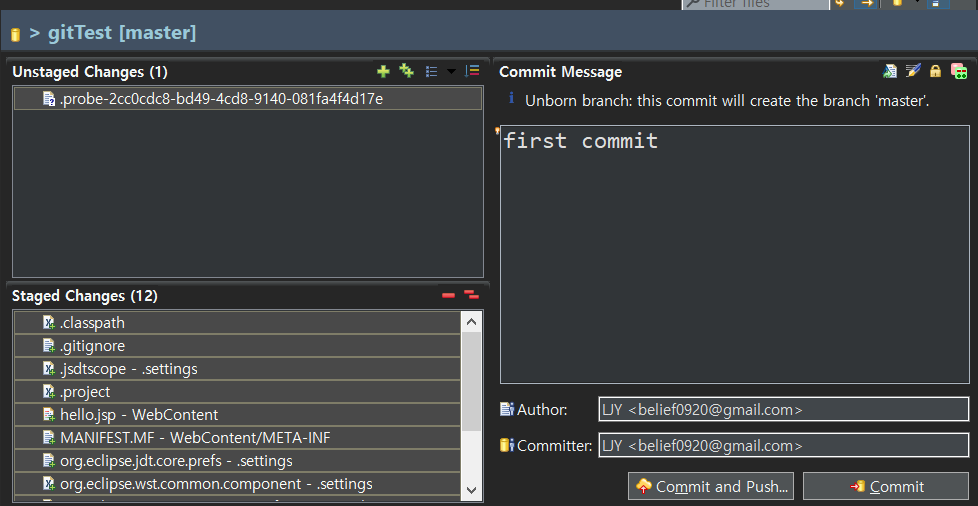
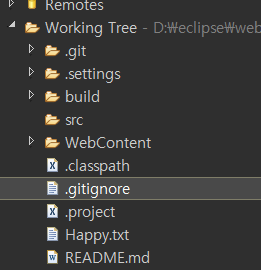
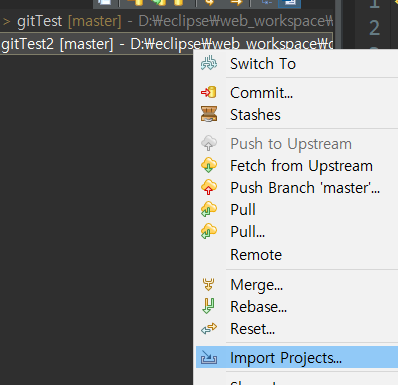
테스트를 하려면 환경 구성이 필요 => 테스트하려는 모듈을 호출하는 모듈(테스트 드라이버) => 테스트하는 모듈이 호출하는 모듈(테스트스텁) => 가상의 모듈을 생성
통합테스트 모듈 통합간에 완성된 모듈간의 호완성을 문제를 찾아내기 위해 수행되는 테스트 빅뱅통합(모두통합한 이후 테스트 진행) => 오류발생한 모듈찾기 힘듬 점진적 통합 기법(점진적으로 모듈을 하나씩 통합하면서 검사 진행 하향식 통합과 상향 통합? => 오류발생 빨리 발견가능
ㅁ .으로 시작하는 폴더는 hidden 폴더(local repository)로 옵션을 사용해서 따로 봐야됨
- 파일 생성 Hello.java
소스를 저장하여 디렉토리에 보관
- git status 저장소 상태 확인 : 추적관리 유무 확인
- git add Hello.java 목록에 추가 : 현재 파일을 관리 파일로 추가
- git commit -m "첫번째 commit 입니다" repostory directory에 저장(이제 지워져도 복구 할 수 있음)
ㅇ 다양한 commit을 좀 더 쉽게 구분하기 위해서
tip. error 뜰 경우 글꼴 문제일 수도 있음 굴림체로 변경
- branch 생성 및 현재 접속 상태 확인
ㅇ 저장하는 상태를 master라고 부름 또 다른 분기점으로second를 만듬
ㅇ 같은 프로젝트인데 다른 기능을 구현하고 싶을 때
ㅁ branch를 통해서 분기점을 나누고 언제든 원상태로 되돌아 갈 수 있다.
ㅁ checkout을 통해 다른 분기점 및 master로 이동가능 하다.
- 파일 수정
ㅇ 다른 분기점에서 원본 파일 수정
- 상태확인(수정된 것을 확인)
modified : Hello.java 파일 수정된 상태 확인
- add, commit 동시 수행
-a : add -m 메세지
- branch master로 이동
- 원본 파일 변경되지 않을 것을 확인 notepad Hello.java
- branch second로 이동
- 동일한 이름의 파일이 master와다른 것을 확인
ㅇ branch로 새로운 분기점을 만든 것이다. 분기점에서 수정시 원본파일은 변경되지 않고
분기점의 파일만 변경된다.
- 수정한 파일이 문제가 없어 다시 master(원본)로 합치고 싶은 경우(지금의 내용)
ㅇ merge를 사용하여 master와 분기점의 파일을 합친다.(master에서 실행하고 병합할 브랜치를 선택)
ㅇ master의 파일도 분기점의 파일과 동일 한 것을 확인 할 수 있다.
- 과거로 돌리기(저장된 commit으로 이동)
ㅇ git log : 언제 commit 했는지 목록을 볼 수 있음
ㅁ commit 뒤에 코드 일종의 지문 같은 것 다양한 사람들이 사용
문제가 발생 시간으로 지정하는게 암호화된 코드로 구분
(문자열 시작부터 6자 길이면 찾을 수 있음.
ㅁ uni코드로 작성되서 요상하게나옴 나중에 툴을 사용하면 메세지 나옴
ㅇ 파일생성(test파일 aaa.txt msg : 오전) => add, commit
ㅇ 파일 생성(test파일 bbb.txt msg : 오후) => add. commit
ㅇ branch에서 분기점을 나누면 파일이 탐색기에서 숨겨지는 것을 확인
ㅁ 파일을 숨길 때 좋음
ㅁ 하나의 파일의 라인의 순서가 바껴도 바꿔줌
tip. 디렉토리라 탐색기를 통해서 확인 가능
ㅇ git log 오전 오후로 파일이 commit된 것을 확인 할 수 있음
ㅇ 국내 로컬용이 아니라 전세계적으로 만듬
ㅁ 국가마다 시간이 다름 => 그래서 유니크한게 만든게 키값
ㅁ 키값 기준으로 전달하는 것임
ㅇ git reset --hard commit 코드
ㅁ 지정한 commit 시점으로 돌아감
ㅁ reset으로 돌아가면 그 시점으로 돌아가서 리셋하기 때문에
이후에 commit된 log들은 모두 소실된다.
ㅁ 인덱스에 등록되어있는 것을 다 찾아서 소스코드 전체를 변경해준다.
- git reset 옵션
ㅇ --soft commit명령만취소, add 명령 실행된 상태
ㅇ --mixed commit,add명령만취소된 상태(생략시 기본값)
ㅇ --hard 그때 시점으로 이동
- git conflict 발생 충돌이 날 때가 있다.
ㅇ merge를 통해 병합 할 때 master(원본수정)와 second(복사본수정)가 다를때 충돌
ㅇ git branch 현재 생성된 master와 분기점을 볼 수 있다.
ㅁ * 표시되어있는 것이 현재 선택된 분기점이다.
ㅇ master branch 파일 변경 Hello.java(원본) => 코드 추가 후 add, commit
ㅇ second로 이동 => 파일 변경 Hello.java(복사폰) => 코드 추가후 add, commit
ㅇ 현재 master(원본수정)와 second(복사본수정) 추가 코드가 다름
ㅇ master 파일과 second 파일을 합병
ㅁ Merge conflict 발생
ㅇ 2파일이 코드가 다른데 덮어버리면 한 파일은 소실 됨
ㅁ 자동으로 현재 작업하고 있는 파일(HEAD : branch master)과
second 작업한 것을 구분 해줌
ㅁ 사용자가 확인 후 파일의 변경된 부분을 상황에 맞게 수정
=> 이런 점 때문에 협업 할 때 주의가 필요함
ㅇ conflict가 발생한 부분을 사용자가 수정 후 add 및 commit => conflict 해결
- gihub란?
ㅇ git과 github는 다른 것
ㅁ git : 형상관리 소프트웨어 : 툴 이름
ㅁ github : 원격 저장소(서버)를 지원해주는 곳 중 가장 유명한 회사)
현재 마소가 인수
ㅇ 로컬 저장소와 원격저장소를 지원
ㅇ 오픈 소스 프로젝트는 무료 지원
ㅇ 인터넷이 되지 않아도 로컬저장소를 사용 할 수 있는게 장점
ㅇ로컬 저장소 .git 뿐만 원격저장소가 있어야 이 기능을 효율적으로 사용하는 것임
ㅇ 원격저장소 중 유명한 곳 (github, atlassian)
- github 가입
ㅇ 공개로 해야 무료인데 올리는 소스에 개인정보가 들어가는 것을 주의해라
- 로컬 저장소를 원격저장소에 연결
ㅇ 로컬 저장소와 원격저장소와 연결 할 수 있는 다리가 생김
ㅁ 오리진 : 원격저장소
ㅁ README란 파일은 관례이다.
README.md 파일명은 git을 사용 할 때 쓰는 관례이다.github_workspace를 디렉토리를 만든 후 초기화로컬에 READE.md 파일을 생성git의 원격 저장소와 현재 로컬저장소를 연결push 원격저장소로 파일을 올린다 => 최초라 깃허브 로그인 필요파일이 생성된 것을 확인생성된 파일의 내용을 볼 수 있다.
- git에 작성한 파일 올려 보기
ㅇ 파일 생성 Test.java 코드 입력 => add 및 commit
ㅇ git remote -v를 통해 연결된 github 주소를 알 수 있다.
ㅇ git push를 통해 github 서버로 파일 업로드
- github에서 로컬저장소로 파일을 옮기는 방법 (clone 사용)
ㅇ 디렉토리 전체를 복사
ㅇ clone or download 버튼을 통해 주소를 복사 할 수 있다.
ㅇ git에서 폴더를 받아 온 것을 확인 할 수 있다.
ㅇ 소스코드 뿐만 아니라 다양한 모든 파일을 올리고 전송 받을 수 있다
ㅇ git에서 받아온 경로를 알 수 있다.
- git에서 파일을 생성해서 코드 작성
Create new file 버튼 클릭파일의 이름을 지정하고 코드 작성상세 설명 및 commit 및 새로운 branch 선택지
- github 파일이동 명령어
ㅇ git clone : 원격 저장소의 모든 내용을 로컬 저장소로 복제(git remote add + git pull)
ㅇ git remote 로컬저장소를 특정 원격 저장소와 연결
ㅇ git push : 로컬 저장소의 내용을 보내거나 로컬 저장소의 변경 사항을
원격저장소로 보낸다.
ㅇ git fetch : 원격저장소로 부터 임시브랜치로 내려받는다.
덮어써지기 때문이다. => 확인후 임시브랜치에서 마스터프랜치로 병합
ㅇ git pull : git remote 명령을 통해서 서로 연결된 저장소의 최신내용을 로컬 저장소로
가져오면서 병합한다.(git fetch + git merge)
- 일부부만 가져오기
ㅇ 오리진/마스터로부터 하나의 커밋을 받아온것을 확인 할 수 있다.
ㅇ 임시 브렌치에 받기때문에 파일이 숨겨져 있다.
ㅇ merge를 통해 현파일과 합치면 볼 수 있다.
- 협업 프로젝트(권한 부여 및 초대)
ㅇ 권한을 부여해서 필요한 인원만 초대하여 진행
ㅇ settings => Manage access => invite a collaborator => 유저이름 및 이메일로 초대
- 협업시 발생하는 문제점
ㅇ 서버 버젼이 갱신되기 때문에(마지막 시간 일련번호를 비교) push pull로 최신화
하고 데이터를 push해야 된다.
ㅇ git 입장에서는 소스를 먼저 올린 사람이 우선이다. => commit을 너무 자주하면 좋지 않다.
ㅇ 로컬은 얼마든지 자주해도 되지만 협업에는 문제가 생긴다
ㅇ 방법 1. 늦게 올린 사람은 git fetch를 통해 수정한 부분만 가져오기
ㅇ 방법 2. git pull을 통해 가져 올 수도 있다.
ㅁ 임시 브랜치로 받아오기 때문에 바로 내 마스터에 적용되지 않는다
ㅁ merge를 통해 임시브렌치에 있는 파일을 병합한다.
ㅁ 충돌 발생하고 사용자가 충돌부분을 처리해야 된다.
ㅁ 충돌 파일을 수정하고 저장 한 후에 add 및 commit 후 git push를 할경우
객체지향 프로그래밍 언어이다. JVM에 의해 운영체제 의존적이지 않고 독립적으로 작동하므로 이식성이 높은 언어이다. Garbage Collecotr에 의해 자동적인 메모리 관리가 가능하다. 기본 자료형을 제외한 모든 요소가 객체로 표현된다. Multi-Thread(다중 동기화)를 지원한다.
장점
단점
2. Java의 메모리 구조에 대해 설명하시오.
Java 프로그램은 운영체제로부터 메모리를 할당받은 JVM의 호출에 의해 실행되므로 독립적이며 JVM에 대해 종속적이라고 할 수 있다. 따라서 작성된 Java 프로그램은 어떠한 운영체제에서도 동일한 결과를 가질 수 있다. 단점으로 JVM을 한 번 더 거쳐 가는 구조이기에 일반 프로그램에 비해 속도가 낮다.
일반 프로그램 : 운영체제(os)의 통제 하에서 메모리를 제어하여 실행(운영체제 종속적)
자바 프로그램 : JVM(Java Virtual Machine)이 운영체제로부터 메모리를 할당받아 프로그램을 실행(JVM 종속적)
JVM의 내부 구조는 크게 Class Loader, Excution Engine, Gabage Collector, Runtime Data Area(Memory Area)로
구성된다.
Java Source Code : 사용자가 작성한 Java Code(.java)
Java Compiler(javac.exe) : Java 코드를 JVM이 읽을 수 있도록 Byte Code(.calss)로 변환
Class Loader : ByteCode(.class)파일을 읽어들여 메모리(Runtime Data Area)에 적재
Execution Engine : 메모리에 적재된 ByteCode를 해석하여 하나의 명령어 단위로 프로그램을 실행
Runtime Data Area : 프로그램을 수행하기 위해 OS에서 할당 받은 메모리 공간 Class Loader에서
준비한 데이터들을 보관하는 저장소
Garbage Collector : 참조되지 않는 객체들을 탐색 후 제거, 삭제된 객체의 메모리를 반환
java에서는 개발자가 프로그램 코드로 메모리를 명시적으로 해제하지 않기 때문에 가비지 컬렉터가 더 이상 필요없는 (쓰레기) 객체를 찾아 지우는 작업을 한다.
Method(Static) Area
인스턴스 생성을 위한 필요 정보를 저장하는 공간이다.(클래스. 변수, Method, static 변수, 상수 정보)
각 데이터는 Runtime Constant Pool(상수 풀)이라는 것을 가지게 되는데, 이는 각 데이터의 Reference를 가지고 있어 실제 물리적 메모리 위치를 참조할 때 사용한다.
(모든 Thread가 공유)
- Constant Pool
상수 풀은 말 그대로 상수를 저장하는 공간이다. 이외에도 필드나 메소드 등의 Reference 값들을 저장하고 있다.
이후, 실행 중에 중복되는 정보가 필요할 때에 기존의 정보를 사용하도록 도와준다.
JVM은 런타임 상수 풀을 통해 해당 메소드나 필드의 실제 메모리상 주소를 찾아 참조
Stack 영역
각각의 메소드를 위한 메모리를 할당 받는데, 이 메소드를 안에서 사용되어지는 값을 저장하며 호출된 메소드의 지역변수, 매게변수, 리턴값 및 연산 값을 임시로 저장하는 공간이다.
Heap영역
동적으로 생성된 객체 또는 배열 등을 저장하는 영역이다. 메소드 영역에서 참조한 값을 바탕으로 새로운 객체를 생성 할 시 이곳에 저장되는데, 사용이 끝난 객체들은 Garbage Collector가 모아 처리한다.
실제로 저장되는 타입은 instance와 Array
(모든 Thread가 공유)
각 스레드마다 하나씩 존재, 스레드가 시작될 때 할당
선입후출(FILO, First In Last Out) 구조로 push와 pop 기능 사용
메서드를 호출 할 때마다 프레임(Frame)을 추가(push)하고 메소드가 종료되면 프레임을 제거(pop)하는 동작을 수행한다.
기본 타입 변수는 스택 영역에 실제값을 가진다.
참조타입 변수는 힙영역이나 메소드 영역의 객체 주소를 가진다.
PC Register
현재 실행되고 있는 JVM의 명령의 주소(Adress)를 가지고 있다. 현재 실행되는 명령이 종료되면 카운트 값을 증가시켜 다음 명령을 실행한다.
(각 Thread별로 하나씩 생성된다.)
Natice Method Area
다른 언어(C/C++ 등)의 메소드 호출을 위해 할당되는 구역으로 언어에 맞게 Stack이 형성되는 구역이다.
총 8가지로 정수형 byte, short, int, long 실수형 float, double 문자형 char 논리형 boolean
참조형(Reference)
stack 메모리 영역에 참조값이 담기고 new 연산자를 통해 실제값을 heap 메모리영역에 저장.
종류 class, interface, array 등이 있음.
4. OOP란? 특징
- OOP의 정의
1. 객체지향 프로그래밍의 요약어로 실세상의 물체를 객체로 표현하고, 이들 사이의 관계, 상호 작용을 코드로 구현한 프로그래밍 방법
2. 객체지향 프로그래밍의 요약어로 데이터를 객체로 취급하여 이를 기준으로 코드로 나누어 구현하는 프로그래밍
방법입니다. 순차적으로 프로그램이 동작하는 절차지향언어와 달리 객체와 객체의 상호작용을 통해 프로그램이 동작합니다.
3. 프로그래밍에서 필요한 데이터를 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법
추가 공부해야 될 것!
-장점
▶코드 재사용이 용이
상속을 통한 재사용과 시스템의 확장이 용이함
▶유지보수가 쉬움
절차 지향 프로그래밍에서는 코드를 수정해야할 때 일일이 찾아 수정해야하는 반면 객체 지향 프로그래밍에서는 수정해야 할 부분이 클래스 내부에 멤버 변수혹은 메서드로 있기 때문에 해당 부분만 수정하면 됨.
▶대형 프로젝트에 적합
클래스단위로 모듈화시켜서 개발할 수 있으므로 대형 프로젝트처럼 여러명, 여러회사에서 개발이 필요할 시 업무 분담하기 쉽다.
자연적인 모델링에 의해 분석과 설계를 쉽고 효율적으로 할 수 있음
사용자와 개발 사이의 이해를 쉽게 해줌
-단점
▶처리속도가 상대적으로 느림
JVM을 거치고 프로그램이 동작하기 때문
▶객체가 많으면 용량이 커질 수 있음
▶설계시 많은 시간과 노력이 필요
프로그래밍 구현을 지원해주는 정형화된 분석 및 설계 방법이 없음
구현 시 처리 시간이 지연됨
OOP의 특징
캡슐화(Encapsulation)란?
데이터와 데이터를 처리하는 함수를 하나로 묶어 다른 객체에게 자신의 정보를 숨기고 자신의
연산만을 통하여 접근을 허용하는 것
방법
1. 접근제한자 private을 사용 필드를 숨김(데이터무결성 유지(보호))
2. 메서드를 통해서만 접근(getter, setter)(어떻게 동작하는지 알 수 없다. 결과만 확인 가능)
데이터와 데이터를 처리하는 함수를 하나로 묶는 것을 의미
캡슐화된 객체의 세부 내용이 외부에 은폐되어. 변경이 발생 할 때 오류의 파급 효과가 적음
은닉화 - 캡슐화에서 가장 중요한 개념으로,다른 객체에게 자신의 정보를 숨기고 자신의
연산만을 통하여 접근을 허용하는 것
캡술화 : 정보은닉(목적)
객체의 속성과 행위를 하나로 묶어 실제 구현 내용은 감추어 은닉한다.(접근 제어자 사용)
캡술화는 클래스가 제공하는 메소드의 기능만을 사용할 뿐 실제 그 메소드가 어떻게 동작하는지는 보여주지 않고
감추는 것이고 은닉화는 클래스의 속성들을 private로 만들어 클래스 밖에서 접근 할 수 없도록 하는 것을 의미한다.
캡술화는 캡술 알약을 생각하자.
약을 복용시 약의 내용물을 확인하지 않고 껍데기만 확인하듯이 마찬가지로 클래스가 제공하는 메소드의 기능만을 사용
할 뿐 실제 그 메소드가 어떻게 움직이는지는 알 필요가 없다.
은닉화는 속성에 직접 접근하는 것은 데이터 무결성에 치명적일 수 있어서 속성들을 접근제어자인 private로 감춰두고getter, setter 메서드를 통해서만 접근 가능하게 하는 것이다.
예) 알약
알약을 뜯어보게 되면 여러가지 성분이 있는데 몸속에 들어가면 각각 알갱이마다 효능이 있을거임
이 알갱이를 데이터 알갱이들을 하는 일을 메서드라 하고 이것을 하나로 묶어둔 것을 캡슐화
감기 걸려서 알약을 사먹을때 감기약들은 제약회사가 다름
알갱이
감기약이 하나가 아님 각각 제약회사가 다르니까 다른 객체에 정보를 숨김
객체의 내용 중 숨기고 싶은 부분을 외부에서 접근 할 수 없게 감추는 것을 의미합니다.
이는 정보의 은닉과 보호 가능합니다.
상속(Inheritance)이란? (재사용 + 상속)
class의 모든 속성과, 연산을 다른 class에게 물려주거나 물려받을 수 있는 것을 의미합니다.
코드를 간결화하고 재사용성을 높일 수 있습니다.
방법
extends 키워드를 통해 상속받을 수 있습니다.
기존 클래스의 기능을 유지하면서 추가적인 기능을 추가하여 클래스를 만들고 싶을 때 사용하는 방법은 상속입니다.
새로운 클래스를 생성 할 때 상위 클래스를 지정함으로써, 상위 클래스의 모든 기능, 속성을 제공받고 자신의 클래승는 부가적인 기능, 속성을 추가 할 수 있습니다. 상속은 코드를 간결화하며, 재사용성을 높일 수 있습니다.
이미 정의된 상위클래스의 모든 속성과 연산을 하위 클래스가 물려 받는 것
상속성을 이용하면 하위 클래스는 상위 클래스의 모든 속성과 연산을 자신의 클래스 내에서
다시 정의하지 않고서도 즉시 사용 할 수 있음.
추상화(abstraction)란? (모델링)
객체의 불필요한 부분을 생략하고 가장 중요한 것에만 중점을 두고 개략화하는 것을 의미합니다.
ex) 스마트폰을 살 때 여러 기종을 보며 비교하교 사게 됨. 이 때 반도체 칩 몇 개?, 회로 구성도는 어떻게 되었는지?
이런 것이 기준이 되는게 아님 공통적인 스펙을 보고 비교해서 구매하게 됨.
만들고자 하는 객체를 추상적으로 선언하고 내부에 들어갈 정보들을 구체화시키는 것을 의미합니다.
직관적인 코드 분석이 가능하다. (=모델링)
불필요한 부분을 생략하고 객체의 속성 중 가장 중요한 것에만 중점을 두고 개략화 하는 것(객체 모델링)
데이터의 공통된 성질을 추출하여 슈퍼클래스를 선정하는 개념
구체적인 것을 분해해서 관심영역에 있는 특성만을 가지고 재조합 하는 것
구체적인 사실들을 일반화시켜 기술한 것
현실 세계에서 다양한 사물의 공통점을 모아서 일반화 시켜 놓은것
불필요한 정보는 숨기고 중요한 정보만을 표현함으로써 공통의 속성이나 기능을 묶어 이름을 붙이는 것이다.
(= 객체지향 관점에서 클래스를 정의하는 것.)
ex) 스마트폰을 살 때 여러 기종을 보며 비교하고 사게 됨. 이 때 이런 공통적인 것을 모델화 한 것?
반도체 칩 몇개?, 스마트폰 좌우에 버튼 몇개, 전기는 어떻게 흐르는지??
다형성(Polimorphism)이란? (사용 편이성)
하나의 타입에 여러가지 객체를 대입해서 다양한 실행결과를 얻는 것을 말한다.
ex) 키보드를 예를 들어보겠다. 키보드는 '누른다'라는 조작으로 동작한다. 하지만 esc는 '종료'를 enter는 '입력'을 나타낸다. 이와같이 동일한 조작방법으로 동작시키지만 동작결과는 다르다.
참고 자료 : 생활코딩, TCP School
하나의 변수명, 함수명 등이 상황에 따라 다른 의미로 해석될 수 있는 것을 의미한다.
오버라이딩(Overriding)과 오버로딩(Overloading)으로 표현한다.
객체들은 동일한 메소드명을 사용하며 같은 의미의 응답함
메시지에 의해 객체가 연산을 수행하게 될 때 하나의 메시지에 대해
각 객체가 가지고 있는 고유한 방법으로 응답 할 수 있는 능력을 의미
5. Object와 Class, Instance에 대해 설명하세요.
Object(객체)는 소프트웨어 세계에 구현할 대상이고, 이를 구현하기 위한 설계도가 Class(클래스)이며 이 설계도에 따라 소프트웨어 세계에 구현된 실체가 Instance(인스턴스)이다.
Objec는 Class의 Instance로 데이터와 데이터에 관련되는 동작이다. 즉, 절차, 방법, 기능을 모두 포함한 개념으로,
변수들과 그와 관련된 메소드들이 모여 이룬 하나의 꾸러미다.
Class(클래스)는 어떤 특정 종류의 모든 객체들에 대해 일반적으로 적용할 수 있는 변수와 메소드를 정의 하고 있는 소프트웨어적인 설계도라 할 수 있다. 실세계에 존재하는 객체들이 가질 수 있는 상태와 행동 들에 대해 소프트웨어적으로 추상화(abstraction) 해 놓은 것.
Instance(인스턴스)는 클래스에 대해 선언, 생성되는 변수이며 메모리 공간을 차지하게 된다. 인스턴스의 메 소드를 이용하여 변수들의 값을 설정 및 변경할 수 있다.
6. Constructor에 대해 설명하시오.
Constructor(생성자)는 OOP에서 쓰이는 객체 초기화 함수로서 객체생성 시에만 호출되어 메모리 생성과
동시에 객체의 데이터를 초기화하는 역할을 한다.
7. this, this()와 super, super()에 대하여 설명하시오.
- this
객체가 자기자신을 지칭할 때 쓰는 키워드
this 참조 변수는 인스턴스가 바로 자기 자신을 참조하는 데 사용하는 변수입니다.
이러한 this 참조 변수는 해당 인스턴스의 주소를 가리키고 있습니다.
this 참조 변수를 사용할 수 있는 영역은 인스턴스 메소드뿐이며, 클래스 메소드에서는 사용할 수 없습니다.
모든 인스턴스 메소드에는 this 참조 변수가 숨겨진 지역 변수로 존재하고 있습니다.
사용목적
객체 내부에서 인스턴스 멤버에 접근하기 위해 this를 사용
매개 변수 이름이 필드와 동일한 경우, 인스턴스 멤버인 필드임을 명시하고자 할 때 사용
- this()
생성자를 호출
this() 메소드는 생성자 내부에서만 사용할 수 있으며, 같은 클래스의 다른 생성자를 호출할 때 사용합니다.
this() 메소드에 인수를 전달하면, 생성자 중에서 메소드 시그니처가 일치하는 다른 생성자를 찾아 호출해 줍니다.
- super
상위 클래스의 인스턴스를 지칭하는 키워드
super 키워드는 부모 클래스로부터 상속받은 필드나 메소드를 자식 클래스에서 참조하는 데 사용하는 참조 변수입니다.
사용할 수 있는 영역은 인스턴스 메소드뿐이며, 클래스 메소드에서는 사용할 수 없습니다.
사용목적
자식 클래스 내부에서 오버라이딩된 부모 클래스의 메소드를 호출해야 하는 상황이 발생
=> 명시적으로 super키워드를 붙여서 부모 메소드를 호출 할 수 있다.
오버라이딩 된 부모 메소드 호출
부모 클래스의 멤버와 자식 클래스의 멤버 이름이 같을 경우 super 키워드를 사용하여 구별
- super()
부모 클래스의 생성자를 호출
부모 생성자는 자식 생성자의 맨 첫줄에서 호출
부모 클래스의 멤버를 초기화하기 위해서는 자식 클래스의 생성자에서 부모 클래스의 생성자까지 호출
8. static 키워드에 대해 설명하세요.
Static 키워드는 클래스를 호출할 때 메모리 공간을 할당하는데 처음 설정된 메모리 공간이 변하지 않음을 의미 한다. 이는 객체를 아무리 많이 만들어도 해당 변수는 하나만 존재(객체와는 무관)한다는 것이다.
인스턴스 필드 정적 필드 선언 판단 기준?
객체마다 가지고 있어야 할 데이터라면 인스턴스 필드로 선언, 객체마다 가지고 있을
필요성이 없는 공용적인 데이터라면 정적 필드로 선언
인스턴스 메서드 정적 메서드 선언 판단 기준?
인스턴스 필드를 이용해서 실행해야 한다면 인스턴스 메서드로 선언, 인스턴스 필드를 이용하지
않는다면 정적 메서드로 선언
사용시 유의사항
정적요소는 클래스 이름으로 접근하는 것이 좋음, 객체 참조 변수로 접근 할 경우 경고
표시를 띄운다(이클립스)
static 메서드에서는 인스턴스 필드나 인스턴스 메소드를 사용 할 수 없음.
this도 사용 할 수 없음.
내부에서 인스턴스 객체를 사용하면서 먼저 생성하고 참조 변수로 접근해야 한다.
static 키워드 변수, 메소드는 처음 설정된 메모리 공간이 변하지 않는다.
이러한 변수와 메소드를 정적 변수, 정적 메소드라고 한다. static을 사용하면 객체를 생성하지 않고 변수나 함수를 사용할 수 있다. 쉽게 접근 할 수 있고 공통의 메모리를 가지기 위해 사용한다.
클래스를 설계하는 경우 공통으로 사용하는 것에 static을 붙여서 사용하며, static을 붙인 메서드는 호출시간이 짧아져서 효율이 높아지는 장점이 있다. 허나 static 변수가 아닌 인스턴스 변수를 static method에서 사용할 수 없기 때문에 설계 시 고려가 필요하다.
13. String과 StringBuffer, StringBuilder의 차이점은 무엇인가?
객채 생성시 공간의 불변성과 가변성의 차이
string 문자열 적은 멀티스레드 stringbuffer 문자열 많은 멀티스레드 stringbuilder 싱글스레드 또느 스레드가 없는
환경
String new 연산을 통해 생성된 String의 인스턴스의 메모리 공간은 절대 immutable(불변)하다
StringBuffer, StringBuilder new 연산으로 생성하고 연산이 필요할 때 크기를 변경시켜 문자열을 변경하므로 mutable(가변)이다.
String은 +연산이나 concat()을 이용해 문자열에 변화를 줘도 기존 메모리 공간이 변하지 않고, new String 객체를 만들어 새로운 메모리 공간에 할당한다. 이렇게 문자열이 다시 생성되면 기존의 문자열은 Garbage Collector에 의해 제거(제거되는 시점은 알 수 없다)된다. 또한 이러한 방식의 연산이 많아지면 계속해 서 객체를 만드는 오버헤드가 발생, 성능이 떨어질 수밖에 없다.
★ String 클래스는 불변이므로 문자열 연산이 적고 조회가 많은 단순 연산과 멀티 스레드 환경에서 사용하면 좋다.
StringBuffer, StringBuilder는 문자열 연산이 자주 있을 때 사용하면 성능이 좋다. 심지어 두 클래스의 메 소드들이 같으므로 혼용되지 않고 사용할 수 있다. 차이점은, StringBuffer는 멀티 스레드 환경에서 Synchronized 키워드의 사용으로 동기화가 가능하여 Thread-Safe 하다. StringBuilder는 동기화를 지원하지 않아 멀티 스레드 환경엔 적합하지 않으나, 싱글 스 레드 환경에선 StringBuffer보다 연산 처리가 빠르다.
★ 문자열이 많을 때 멀티 스레드 환경은 StringBuffer, 싱글 스레드 또는 스레드가 없는 환경에서는 StringBuilder가 성능이 좋다.
14. 배열과 ArrayList의 차이점
배열이나ArrayList나데이터타입이모두같으면서하나이상의값을집합한저장소이다.배열의경우는초기에 배열의 크기를 정해야 한다.ArrayList의경우는동적으로 추가적인 할당이가능하다.배열이 속도 더 빠르다
15. Wrapper Class에 대해 설명하시오.
Primitive Type으로 예를들어 collection을 반환 할 필요가 있을 때
객체로 만들어야 할 경우가 있다. 이 때 이러한 기능을 지원하는 클래스다.
정수형 int와 문자형 Char만 이름이 다르며 다른 기본형은 동일하고 첫글자가 대문자입니다.
자바의 기본자료형(int, float, double, byte, char 등)을 위한 클래스
매개변수가 객체이거나 반환값이 객체인 경우 기본자료형을 객체형으로 사용한다.
int의 Wrapper클래스는 Integer로 해당 클래스의 parseInt 메소드를 활용하여 문자열로 취급되는 "1"을 숫자로 반환할수도 있다.
또한, 컬렉션 프레임워크의 제네릭으로 타입을 지정해 주는 경우 Wrapper 클래스를 써야 한다.
16. 쓰레드와 프로세스?
프로세스는 프로그램에 대한 각각의 인스턴스(독립적인 객체)를 의미한다. 프로세스는 운영체제로부터 주소공간, 파일, 메모리 등을 할당 받는다.
프로세스 :컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램, 프로세스는 운영체제로부터 주소공간, 파일, 메모리 등을 할당받는다.
프로세스란 운영체제가 프로그램에 메모리를 할당하여 연속적으로 실행하는 것을 의미하며 운영체제로부터 주소공간, 파일, 메모리 등을 할당받는다.
스레드란 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들을 대부분 공유하면서 실행된다.
멀티스레드란 하나의 프로그램에서 둘 이상의 프로세스가 필요할 때 사용된다. 자원을 효율적으로 사용하고 프로세스가 분리되어 코드가 간결해진다.
프로세스는 자신만의 고우공간과 자원을 할당 받아 사용하는데 비해 스레드는 다른 스레드와 공간과 자원을 공우하며 사용한다. 기본적으로 하나의 프로세스가 생성되면 하나의 스레드가 같이 생성된다. 이를 메인 스레드고 부르며, 스레드를 추가로 생성하지 않는 한 모든 프로그램 코드는 메인 스레드에서 실행된다. 또한 프로세스는 여러 개의 스레드를 가질 수 있으며 이를 멀티 스레드라고 한다.
스레드의 장점
시스템의 자원소모가 줄어든다.
프로그램의 응답시간이 단축된다.
프로세스간 통신방법에 비해 스레드간의 통신방법이 훨씬간단하다.
시스템의 스루풋이 향상된다. 스루풋 : 주어진 시간 동안 컴푸터 할 수 있는 일의 양
스레드의 단점
프로그램 디버깅이 어렵다.
여러 개의 스레드를 이용하는 프로그램을 작성하는 경우에는 미묘한 시간차나 잘못된 변수를 공우함으로써 오류가 발생할 수 있다.
교착상태에 빠질 수 있다.
서로 데이터를 사용하다가 충돌이 일어날 가능성이 있습니다.
디버깅이 다소 까다로워 집니다. (버그 생성될 가능성 증가)
Thread를 구현하기 위한 방법
상속(extends)해서 쓰려면 Thread Class 를 상속받으면 되고 구현(implements)해서 쓰려면 Runnable 인터페이스를 구현하면 된다.
스레드 생성은 스레드 클래스를 상속받거나 Runnable 인터페이스를 구현 받는 방법과 구현한 클래스 내부에서 인스턴스 생성 즉 스레드를 생성시키는 방법이 있다.
17. 제네릭(Generics)이란?
Generic Type(제네릭 타입)은 자바 5부터 추가된 것인데, 이를 이용해 잘못된 타입이 사용될 수 있는 문제를 컴파일 과정에서 제거할 수 있게 되었다. 제네릭은 클래스와 인터페이스, 그리고 메소드를 정의할 때 Type(타입)을 Parameter(파라미터)로 사용할 수 있도록 하는데, 타입 파라미터는 코드 작성 시 구체적인 타입으로 대체되어 다양한 코드를 생성하도록 해준다. ▶이점 : 컴파일 시 강한 타입 체크 가능(실행 시의 타입 에러 > 컴파일 시 미리 강하게 타입 체크) ▶이점 : Casting(타입 변환) 제거(비제네릭 코드는 불필요한 타입 변환으로 프로그램 성능에 악영향)
클래스 내부에서 사용할 데이터타입을 외부에서 지정하는 기법으로 데이터타입의 일반화라고 합니다.
사용목적
컴파일시 강한 타입체크를 통해잠재적인 예외를 사전에 잡아낼 수 있다.
타입변환(casting)을 제거한다.(비제네릭 코드는 불필요한 타입 변환으로 프로그램 성능에 악영향)
코드의 중복을 줄여주어, 코드의 재사용성 높이고 시간을 절약 할 수 있다.
참고
Object 사용시에 모든 데이터를 받아 올 수 있지만 사용시 형변환이 필요하다.
정의 : 모든 종류의 타입을 다룰 수 있도록 일반화된 타입 매개 변수(generic type)로 클래스나 메서드를 선언하는 기법
사용이유?
컬렉션 클래스에서 제네릭을 사용하면 컴파일러는특정 타입만 포함될 수 있도록 컬렉션을 제한합니다.
컬렉션 클래스에 저장하는 인스턴스 타입을 제한하여런타임에 발생할 수 있는 잠재적인 모든 예외를 컴파일타임에 잡아낼 수 있도록도와줍니다.
제네릭 타입을 이용해서 컴파일 과정에서 타입 체크를 할 수 있다.
제네릭은 클래스와 인터페이스, 메소드를 정의할 때 타입 파라미터로 사용한다.
* 제네릭을 사용하는 이유(=장점)
1. 컴파일할 때 타입을 체크해서에러를 사전에 잡을 수 있다.
2. 컴파일러가타입캐스팅을 해주기 때문에 개발자가 편리하다.
3. 타입만 다르고 코드의 내용이 대부분 일치할 때,코드의 재사용성이 좋아진다.
18. collection framework에 대해 설명하시오.
LIST, SET, MAP이 있다.
LIST는 순서가 있는 데이터의 집합으로 데이터의 중복을 허용한다.
SET은 순서를 유지하지 않는 데이터의 집합으로 중복을 허용하지 않는다.
MAP은 Key와 Value의 쌍으로 이루어진 데이터의 집합니다. 순서는 유지되지 않도,
키는 중복을 허용하지 않으며값의 중복은 허용한다.
다수의 데이터를 쉽고 효과적으로 처리 할 수 있는 표준화된 방법을
제공하는 클래스의 집합
데이터를 저장하는 자료구조와 데이터를 처리하는 알고리즘을 구조화하여
클래스를 구현해 놓은 것
인터페이스를 사용하여 구현
제네릭으로 표현
19. list의 종류에 대해 설명하시오.
20. set의 종류에 대해 설명하시오.
21. map의 종류에 대해 설명하시오.
22. vector와 arraylist의 차이점을 설명하세요.
23. 객체의 직렬화(Serialization)란?
Serialize(직렬화)란 Java 내부에서 사용되는 객체 또는 데이터를 외부의 Java 시스템에서도 사용할 수 있도 록 byte 형태로 데이터 변환하는 기술과 byte로 변환된 데이터를 다시 객체로 변환하는 기술(역직렬화)를 아울러서 이야기한다.
장점
장점은 Java 시스템에서 개발에 최적화 되어 있다는 점이다. 복잡한 데이터 구조의 클래스 객체라도 직렬화 기본 조건만 지키면 바로 직렬화, 역직렬화가 가능하다. 또한 데이터 타입이 자동으로 맞춰지기 때문 에 관련 부분을 신경쓰지 않아도 된다.
단점
자바 직렬화를 이용해서 외부 데이터를 저장하게 되면 자바에서만 사용할 수 있는 문제
언제 사용되나?
JVM의 메모리에서만 상주되어있는 객체 데이터를 그대로 영속화(Persistence)가 필요할 때 사용됩니다. 시스템이 종료되더라도 없어지지 않는 장점을 가지며 영속화된 데이터이기 때문에 네트워크로 전송도 가능하다.
예 : 서블릿 세션, 캐시, 자바 RMI
사용방법
Serializable 인터페이스를 구현
객체에 직렬화가 제한되는 데이터가 있을시 transient 키워드를 붙여 대상에서 제외 가능
다른 데이터 직렬화 종류
문자열 형태 => 범용적인 API나 데이터를 변환하여 추출할 때 많이 사용,대표적인 예로 CSV, JSON이 있다.
-MVC란 Model, View, Controller로 나누어 비즈니스로직과 유저인터페이스를 분리하여 서로 영향없이 유지보수가 용이하게 개발할 수 있습니다.
MVC 구성요소
Model -논리적 데이터 기반 구조를 표현, (데이터)
View -사용자 인터페이스 내의 구성요소들을 표현(사용자에게 보여지는 화면)
Controller -Model과 View를 연결하고 있는 상호 동작을 관리, Model과 View 내의 클래스들 간
정보 교환을 하는데 사용
사용자의 입력을 받아 이벤트를 처리하고 그 결과를 다시 사용자에게 표시하기 위한 최적화된 설계를 가지고 있다.
3. model1과 model2의 차이점은?
모델1 방식을 채택하면빠르고 쉽게 개발할 수 있다는 장점이 있다. 하지만, JSP 파일 자체가 너무 비대해지고, Controller와 View가 혼재하므로 향후유지보수에 어려움을 겪을 수 있다.
클라이언트에서 request(요청)을 받아들이고 클라이언트에 response(응답)해주는 처리를 jsp단독으로 처리하는 구조
모델2 방식은 View와 Controller를 분리하는 방식이다. 그래서디자이너와 개발자의 분업이 가능하며 유지보수에 유리하다. 하지만설계에서 어려움을 겪을 수 있고, 개발 난이도가 높다는 단점이 있다. (설계가 잘못될 경우, 웹 애플리케이션 전체가 망가질 수 있다.)
요청처리, 데이터베이스 접근, 비즈니스 로직을 포함하고 있는 컨트롤 컴포넌트와 뷰 컴포넌트가 엄격하게 분리되어 뷰에서는 어떠한 로직도 포함하고 있지않다.
개발의 난이도와 유지보수의 차이점이 있습니다.
디자이너와 개발자의 분업 가능
4. Singleton에 대해 설명 하시오.
1. 쿠키와 세션에 대해서 설명
1. 세션
- 지정한 정보를 서버에 남겨두고 클라이언트에는 세션 정보만을 남겨두어 클라이언트에서 정보가 필요할때
저장된 세션정보를 서버에 전달하여 서버에서 해당 세션에 저장된 정보를 가저오는 방식.
2. 쿠키
- 지정항 정보를 클라이언트쪽에 고스란히 남겨두고 필요할때마다 클라이언트에서 바로 사용하는 방식.
지정된 정보가 클라이언트쪽에 그대로 남아있기때문에 악의적으로 사용될 여지가 있다.
3.공통점
- 헤더가 시작하기 전에 사용해야한다.
세션은 서버에 저장되는 값이며, 쿠키는 클라이언트에 저장되는 값입니다.
Session과 Cookie 사용 이유
현재 우리가 인터넷에서 사용하고 있는 HTTP 프로토콜은 연결 지향적인 성격을 버렸기 때문에 새로운 페이지를 요청할 때마다 새로운 접속이 이루어지며 이전 페이지와 현재 페이지 간의 관계가 지속되지 않는다. 이에 따라 HTTP프로토콜을 이용하게 되는 웹 사이트에서는 웹 페이지에 특정 방문자가 머무르고 있는 동안에 그 방문자의 상태를 지속시키기 위해 쿠키와 세션을 이용한다.
Session
- 특정 웹사이트에서 사용자가 머무르는 기간 또는 한 명의 사용자의 한번의 방문을 의미한다.
- Session에 관련된 데이터는 Server에 저장된다.
- 웹 브라우저의 캐시에 저장되어 브라우저가 닫히거나 서버에서 삭제시 사라진다.
- Cookie에 비해 보안성이 좋다.
Cookie
- 사용자 정보를 유지할 수 없다는 HTTP의 한계를 극복할 수 있는 방법
- 인터넷 웹 사이트의 방문 기록을 남겨 사용자와 웹 사이트 사이를 매개해주는 정보이다.
- Cookie는 인터넷 사용자가 특정 웹서버에 접속할 때, 생성되는 개인 아이디와 비밀번호, 방문한 사이트의 정보를 담은 임시파일로써, Server가 아닌 Client에 텍스트 파일로 저장되어 다음에 해당 웹서버를 찾을 경우 웹서버에서는 그가 누구인지 어떤 정보를 주로 찾았는지 등을 파악할 때 사용된다.
- Cookie는 Client PC에 저장되는 정보이기 때문에, 다른 사용자에 의해서 임의로 변경이 가능하다.( 정보유출 가능, Session보다 보안성이 낮은 이유 )
Q. 보안성이 낮은 Cookie대신 Session을 사용하면 되는데 안하는 이유?
A. 모든 정보를 Session에 저장하면 Server의 메모리를 과도하게 사용하게 되어 Server에 무리가 가게 된다.
9. Servlet과 JSP에 대해 설명해 보세요.
컨테이너란?
servlet container - 서블릿을 실행하기 위한 서버 소프트웨어(아파치 톰캣이 대표적)
jsp나 서블릿으로 만들어진 웹 프로그램을 개발하고 실행하기 위한 환경
Container(컨테이너)는 보통 인스턴스의 생명주기를 관리하며 생성된 인스턴스들에게 추가적인 기능을 제공한다. 컨테이너란 작성된 코드의 처리과정을 위임받은 독립적인 존재로, 적절한 설정만 되어 있다면 누구의 도움 없이 프로그래머가 작성하는 코드를 스스로 참조하여 알아서 객체의 생성과 소멸을 컨트롤 해준다. Servlet Container는 Servlet의 생성, 초기화, 서비스 실행, 소멸에 관한 모든 권한을 가지고 있다. 또한 JSP/Servlet 접근 권한에 대한 추가적 서비스도 지원하며 구현과는 별도로 Security를 관리해주는 기능을 한다
Servlet
JAVA코드안에 HTML태그가 삽입되어 만들어지며 확장자는 .java이다.(Html in Java)
서버에서 웹페이지 등을 동적으로 생성하거나 데이터 처리를 수행하기 위해 자바로 작성된 프로그램
특징 - main 메서드가 없으며, 서블릿 컨테이너에 등록된 후 서블릿 컨테이너에 의해 생성, 호출, 소멸이 이루어짐.
JSP(Java Server Page) - html기반에 JAVA코드를 블록화하여 삽입한 것(JAVA in Html)
HTML 코드에 JAVA 코드를 넣어 동적웹페이지를 생성하는 웹어플리케이션 도구이다.
서블릿의 단점을 보완해서 만든 서블릿 기반의 스트립트 기술
JSP 가 실행되면 자바서블릿(Servlet)으로 변환되며웹 어플리케이션 서버에서 동작되면서 필요한 기능을 수행하고
데이터정의언어 : DB구조, 데이터형식, 접근 방식등 DB를 구축하거나 수정 할 목적으로 사용하는 언어
데이터 조작언어 : 사용자로 하여금 데이터를 처리할 수 있게 하는 도구로서 사용자와 DBMS간의 인터페이스 제공
데이터 제어언어 : 무결성, 보안 및 권한 제어, 회복 등을 하기 위한 언어
트랜잭션 : 데이터베이스 내에 하나의 그룹으로 처리해야 하는 명령문을 모아놓은 작업단위 또는 데이터 처리의 한 단위
데이터베이스의 논리적인 작업단위. 전부 적용하거나 전부 취소. All or Nothing
4. oracle, mysql, mssql, 등을 부르는 종류명은?
5. Merge에 대해 설명하시오.
6. Index에 대해 설명하시오.
5. 데이터베이스 설계시 정규화를 하는 이유는?
데이터의 중복을 최소화하고 테이블의 삽입, 삭제, 갱신 과정에서 발생하는 이상현상을 방지하기 위함입니다.
이상현상 예시
갱신 이상(Modification Anomaly): 반복된 데이터 중에 일부를 갱신 할 시 데이터의 불일치가 발생한다.
삽입 이상(Insertion Anomaly): 불필요한 정보를 함께 저장하지 않고서는 어떤 정보를 저장하는 것이 불가능하다.
삭제 이상(Deletion Anomaly): 필요한 정보를 함께 삭제하지 않고서는 어떤 정보를 삭제하는 것이 불가능하다.
6. 기본키와 외래키 설명
기본키 : 해당 컬럼
7. join이란?
2개 이상의 테이블을 마치 하나의 테이블처럼 연결하고 올바른 연결을 위한 조건을 부여(조인 조건)
잘 못된 조견 부여시 중복되는 데이터 발생
Join이란 2개 이상의 테이블에서 조건에 맞는 데이터를 추출하기 위하여 사용
8. 서브쿼리란?
SELECT문 안에 다시SELECT문이 기술된 형태의 쿼리(query)입니다. 앞서 쿼리와SELECT문은 같은 의미라고 했습니다. 서브쿼리(하위SELECT문)의 결과를 메인 쿼리(상위SELECT문)에서 받아 처리하는 구조이기 때문에 중첩된(nested)쿼리라고도 부릅니다. 서브쿼리의 결과는 메인 쿼리의 조건으로 사용됩니다. 단일SELECT문으로 조건식을 만들기에는 조건이 복잡할 때 또는 완전히 다른 테이블에서 데이터 값을 조회하여 메인 쿼리의 조건으로 사용하려 할 때 유용합니다. 이를테면 서브쿼리는 두 번 작성해서 결과를 출력해야 하는SELECT문을 한 번만 작성해서 처리할 수 있도록 합니다.
9. where와 having의 의미
HAVING과 WHERE 은 둘 다 쿼리에 조건을 부여한다는 공통점이 있다.
HAVING은 SELECT 문에서 사용된 그룹이나 aggregate function(AVG, SUM, MIN, MAX, VAR,COUNT, GROUPING, STDEV 등)에 조건을 부여해서 결과를 세분화한다. SELECT 문과 함께만 사용할 수 있으며, 주로 GROUP BY와 함께 쓰인다. 그룹화된 결과에만 적용될 수 있다. 반면, WHERE은 개별 행에 적용된다. 두 구문이 함께 쓰일 수도 있다. 둘 중 하나가 더 빠르거나 하지는 않다.
Having절은 그룹함수의 그룹의 조건으로 사용되고, where 절은 select할 데이터에 조건을 주는 역할입니다.
10. view에 대해 설명
- 물리적 테이블의 근거한 논리적 가상테이블 역할
ex)창문을 통해 비치는 배경
- SELECT문 몇 개로아주 작은 바이트로 테이블을 복사해놓는 효과
- 별도의 저장장소 부여하지 않고 실행하는 순간 서브쿼리 동작 - 원본이 수정되면 같이 수정된 것 처럼 보임
- 뷰는 실제 테이블의 일부를 잘라 보여준다.
- 자주 쓰는 것에 이름을 부여
장점
- 보안에 유용 (ex)부서별로 볼 수 있는 정보의 제한) - 액세스의 단순화 (ex)알바가 몰라도 할 수 있다)
가상의 테이블이라 하며, View에는 데이터가 들어있는 것이 아닌 SQL에만 저장되어 있음.
View를 사용하는 이유는 보안과 사용자의 편의성 때문. 만약 어떤 테이블에 대해 다른 사용자가 봐서는 안되는 칼럼이 있다면 view를 사용하여 정의된 쿼리의 결과만 볼 수 있게 할 수 있다.
허용된 데이터를 제한적으로 보여주기 위해 하나 이상의 테이블에서부터 유도된 가상 테이블
=>사용자가view에 접근했을 때 해당하는 데이터를 원본에서 가져옴.
뷰에 나타나지 않은 데이터 보호 가능+편의성
11. Group by란?
하나 이상의 열을 기준으로그룹을 묶어서 결과를 가져오는 집계함수 입니다. 쉽게 말하면그룹단위로 묶어서 결과를 도출한다라고 생각하면 될듯합니다,
- 특정 컬럼을 기준으로 그룹화하여 테이블에 존재하는 행들을 그룹별로 구분하기 위해 사용한다.
- 그룹 함수를 쓰되, 어떤 컬럼값을 기준으로 그룹 함수를 적용할지 기술해야 한다.
HAVING ~
- GROUP BY 절에 의해 생성된 결과 값 중 원하는 조건에 부합하는 자료만 보고자 할 때 사용한다.
- HAVING 그룹에 대한 제한 / WHERE은 ROW에 대한 제한
12. Order by란?
SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 칼럼을 기준으로 정렬하여 출력 하는데 사용
- 오름차순 : ASC,ORDER BY (기본값)
- 내림차순 : DESC
13. PK랑 UK의 차이점
기본키는 널을 허용하지 않지만 유일키는 모든 컬럼 중 유일하게 하나에 대한 NULL을 허용합니다. 그래서 unique키는 개체하나하나를 구분할 기본키가 될 수 없다.
14. INNER JOIN과 OUTTERJOIN의 차이점
두 join의 차이는 차집합 행의 포함 여부입니다.
inner join은 조인하는 테이블에 일치하는 값이 없는 행은 제외시키고 outer join은 일치하지 않은 값을 포함시킵니다.
16. 기본키, 외래키, 인덱스의 의미와 어떻게 사용할지 주관적인 생각을 이야기해 주시기 바랍니다.
17. Oracle과 mysql 중 뭐가 더 좋은가? 그 이유는?
[Framework]
1. 프레임워크가 무엇인가?
애플리케이션 개발에 바탕이 되는 템플릿(뼈대)과 같은 역할을 하는 클래스와 인터페이스들의 집합
프로그램의 기본 구조(뼈대)로서 그 자체만으로 움직이지 않으나 필요한 기능을 한데 모아 구축해놓은 것
2. 스프링 프레임워크란?
자바(JAVA) 엔터프라이즈 개발을 위한 "오픈소스(Open Source)" 애플리케이션 프레임워크(Framework)
Open Source : 소프트웨어(S/w) 혹은 하드웨어의(H/W) 제작자의 권리를 지키면서 원시 코드를 누구나 열람할 수 있도록 한 소프트웨어, 오픈 소스 라이선스에 준하는 모든 통칭을 일컫는다. (소스가 공개되어 여러 개발자가 플랫폼을 함께 개발, 구축, 보완해 나가는 시스템. )
3. 스프링의 특징에 대해서 설명해 보세요.
1)경량 컨테이너로서 자바 객체를 직접 관리.
각각의 객체 생성, 소멸과 같은 라이프 사이클을 관리하며 스프링으로부터 필요한 객체를 얻어올 수 있다. 2) 스프링은POJO(Plain Old Java Object) 방식의 프레임워크.
일반적인 J2EE 프레임워크에 비해 구현을 위해 특정한 인터페이스를 구현하거나 상속을 받을 필요가 없어 기존에 존재하는 라이브러리
등을 지원하기에 용이하고 객체가 가볍다. 3) 스프링은 제어 반전(IoC: Inversion of Control)을 지원.
컨트롤의 제어권이 사용자가 아니라 프레임워크에 있어서 필요에 따라 스프링에서 사용자의 코드를 호출한다. 4) 스프링은 의존성 주입(DI: Dependency Injection)을 지원
각각의 계층이나 서비스들 간에 의존성이 존재할 경우 프레임워크가 서로 연결시켜준다. 5) 스프링은 관점 지향 프로그래밍(AOP: Aspect-Oriented Programming)을 지원
따라서 트랜잭션이나 로깅, 보안과 같이 여러 모듈에서 공통적으로 사용하는 기능의 경우 해당 기능을 분리하여 관리할 수 있다. 6) 스프링은 영속성과 관련된 다양한 서비스를 지원
iBatis나 Hibernate 등 이미 완성도가 높은 데이터베이스 처리 라이브러리와 연결할 수 있는 인터페이스를 제공한다. 7) 스프링은확장성이 높음.
스프링 프레임워크에 통합하기 위해 간단하게 기존 라이브러리를 감싸는 정도로 스프링에서 사용이 가능하기 때문에 수많은 라이브러리
가 이미 스프링에서 지원되고 있고 스프링에서 사용되는 라이브러리를 별도로 분리하기도 용이하다.
5. 스프링 MVC의 흐름에 대해서 설명해보세요.
6. 관점지향프로그래밍(AOP)에 대해서 설명해 보세요.
ㅇ 여러 객체에 공통으로 적용 할 수 있는 기능을 분리함으로써 재사용을 높여주는 프로그래밍 기법
ㅇ 간단하게핵심 기능에 공통 기능을 삽입하는 것
ㅇ핵심 기능의 코드를 수정하지 않으면서 공통 기능의 구현을 추가하는 것
7. DI패턴에 대해서 설명해 보세요.
7.
[Infra]
8. Mybatis에 대해서 설명해 보세요.
MyBatis란?
객체 지향 언어인 자바의 관계형 데이터 베이스 프로그래밍을 보다 쉽게 도와주는 프레임 워크 데이터베이스와 객체를 맵핑해주는 프레임 워크 MyBatis의 특징 1.SQL문이 코드로부터 완전히 분리: 기존에는 DAO파일에 모든 SQL문을 작성하였다. 하지만 MyBatis에서는 Mapper 파일에 SQL코드를 입력해 놓고 DAO 파일에서 필요할 때마다 가져와서 사용할 수 있다. 2.생산성: 코드가 짧아진다. 3.유지보수성 향상: Mapper 파일에만 SQL 코드를 입력하고 나중에 SQL 코드를 변경할 때 이곳에서 유지보수만 하면, DAO에서는 아무런 영향을 받지 않는다. 왜냐하면 DAO에서는 Mapper파일에서 작성된 SQL 코드를 갖다 쓰기만 하기 때문이다.
1. DB 설치 : Java <==> DB : OUI 2. JDK 설치 3. 환경변수 설정
제어판\사용자 계정 및 가족 보호\사용자 계정 사용자계정 컨트롤 변경
1 .이메일 입력하는 부분 없어도 설치하는데 지장없음 => 다음
2. 데이터베이스 생성 및 구성
3. 데스크톱 클래스
4. 설치 할 경로 C드라이브 => 문자집합 WIN949 => DB이름 orcl PW orace => 권장비밀번호가 아닙니다. 진행 => 전체 엑세스 허용
tip lsnrctl listener controller 리스너 관리프로 그램 db에 연결하려면 얘를 항상 거치고 가야됨 얘가 꺼져 있으면 로컬에서 되지만 외부에서 접속이 안 됨 status 상태 확인 할 수 있음 help 키워드를 통해 명령어를 알 수 있음.(start, stop, status)
자바 설치 설정없이 계속 진행
=> cmd javac -version 설치 확인 path 하면 현재 환경변수 설정 확인 할 수 있음 환경변수를 찾을 때 앞에 부터 찾음. 그래서 자주 사용 할 경우 앞에 환경변수를 적요하는게 좋음.
제어판\시스템 및 보안\시스템 => 고급 시스템 설정
PATH, CLASSPATH, JAVA_HOME 설정 (; 입력값 하나 일경우 ; 할 필요없음) PATH : 맨 앞에 C:\Program Files\Java\jdk1.8.0_221\bin; CLASSPATH : . JAVA_HOME : C:\Program Files\Java\jdk1.8.0_221
새창을 띄울 때 적용되기 때문에 Restart (재부팅)
환경변수 설정 위에 환경변수 로그인한 사용자 적용 아래꺼 로그인 상관없이 모든 사용자 적용
이클립스 설치 1. C드라이브 압축 해제 2. workspcae 폴더 설정(web_workspace)
3. encoding 언어 UTF-8 변경 4. 현재 사용 할 프로젝트(web) import => 톰캣 없어서 오류 발생
tomcat9 설치 => 폴더명 변경(tomcat9)
설치 할 드라이브에 압축 해제
다른 경로로 저장 할 때 Java가 특정 임의의 폴더에 담겨 있을 때 JRE_HOME 에러 발생 C:\tomcat9\conf\server.xml 1. 오른쪽 마우스 편집 실행 2. 8080으로 찾기(TEST로 띄우는 포트) => 상용화시(80 사용) 3. URIEncoding="UTF-8" 추가 4. bin 폴더 startup.bat 톰캣 실행 확인 5. 이클립스 서버 생성 6. 톰캣9 선택 톰캣 디렉토리 설정 C:\tomcat9
os에있는 config컨피그레이션? 톰캣을 생성 라이브러리에 톰캣9 생성 된것을 확인 할 수 있음
window => 웹브라우저 => 크롬 선택
aptana(플랫폼을 교차해서 사용)
emmet 설정(emmet 사이트 다운로드 링크복사) 1. help => install new software => 복사한 링크 지정 2. 모드 끝내고 restart now